
С ростом корпоративных облачных хранилищ усиливается эффект Data Gravity — явление, при котором большие объёмы данных формируют притяжение для вычислительных процессов. Когда терабайты и петабайты датасетов концентрируются в одном регионе S3‑совместимого хранилища, вычисления от ETL‑пайплайнов до AI‑инференса неизбежно "оседают" ближе к источнику, снижая затраты на межрегиональный трафик. Попытки обработки за пределами региона приводят к росту latency, увеличению replication lag и финансовым затратам на outbound‑трафик.

Для Serverspace с multiregion‑сетями (RU, IO, US, KZ and etc) этот эффект критичен при масштабировании AI‑нагрузок: высокая плотность обращений к S3‑данным и необходимость синхронного доступа к весам нейросетей приводят к смещению Kubernetes‑кластеров и BI‑сервисов в регионы с минимальной задержкой и максимальной пропускной способностью. Data Gravity становится не просто теоретическим эффектом, а наблюдаемым фактором, оказывающим прямое влияние на производительность приложений, архитектуру сетей и финансовую эффективность распределённой инфраструктуры.
Что такое Data Gravity простыми словами
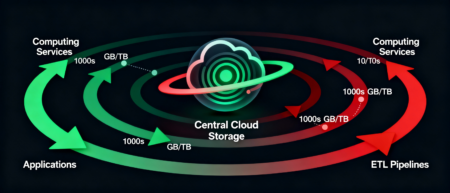
Data Gravity — это концепция, описывающая, как большие объёмы данных создают «притяжение» для вычислительных процессов, приложений и сервисов. Чем больше данных хранится в определённой инфраструктуре и чем выше частота обращений к этим данным, тем сложнее и дороже становится их перемещение или обработка за её пределами.
В терминах облачных систем это означает, что при попытке запустить вычисления в другом регионе или облаке возникают дополнительные сетевые задержки, избыточное потребление пропускной способности и прямые финансовые затраты. Например, если ETL‑пайплайн Serverspace обращается к данным, хранящимся в S3‑совместимом хранилище региона RU, и пытается обработать их в AWS Lambda в регионе
us-east-1, то производительность падает значительно из-за сетевого лага, репликации данных между облаками и необходимости повторной синхронизации результатов.
Этот эффект проявляется не только в облачных средах, но и в локальных Data Warehouse и on-premise решениях: чем больше объём данных, тем выше стоимость и время их перемещения, что заставляет инженеров размещать вычисления максимально близко к источнику данных на уровне физической архитектуры.
Как проявляется эффект в инфраструктуре
В инфраструктуре Serverspace эффект Data Gravity проявляется особенно остро при работе с крупными объёмами в S3‑совместимых хранилищах и многорегиональных сценариях. Технически это фиксируется ростом сетевых задержек (latency) и падением доступной пропускной способности между зонами — например, RU, NL, KZ — по мере увеличения общего объёма данных, интенсивности операций и числа одновременных запросов.
Ключевые технические проявления Data Gravity:
- Латентность между регионами и деградация performance. При перемещении больших бакетов (например, с 100 ГБ до 3 ТБ) средние задержки доступа к данным по сети могут увеличиваться с 38 мс до 80–90 мс даже между относительно близкими регионами из-за перегрузки маршрутизаторов, увеличения фрагментации пакетов и необходимости повторной передачи потерянных данных. Интерконтинентальная задержка между датацентрами Европы, России, Казахстана и другими локациями ещё выше (200–500 мс) и экспоненциально чувствительна к объёму операций в секунду, типу данных и сетевому congestion.
- Рост outbound‑трафика, расходы на трафик и финансовые издержки. При распределённых вычислениях дополнительные сетевые расходы возникают на каждый межрегиональный пакет данных, особенно если датасеты "размазываются" по разным кластерам или зонам хранения. Это требует продуманного финансового учёта — например, внутренний трафик между виртуальными машинами Serverspace и объектным хранилищем в одной зоне доступности не тарифицируется, а внешний межрегиональный трафик приводит к удорожанию нагрузки на 50–200% в зависимости от направления маршрута.
- Производительность I/O, pipelined операции и консолидация. Чем ближе данные размещены к вычислениям (идеально в одной availability zone), тем выше общая пропускная способность за счёт снижения RTT (round-trip time) и лучшей утилизации кэшей процессора. Меньше вероятность узких мест при одновременной работе ETL, ML‑пайплайнов и BI‑нагрузки. Попытка реплицировать или оперативно синхронизировать большие объёмы между регионами приводит к заметным репликационным задержкам (replication lag) вплоть до нескольких минут при массовых изменениях и высокой частоте write-операций.
Современные сценарии работы с большими файлами (видеоархивы, весовые коэффициенты больших языковых моделей, лог‑архивы для security analytics, genomic datasets) показывают, что latency‑чувствительные сервисы в реальности вынуждены консолидироваться там, где находится основной "гравитационный" массив данных — обычно в рамках одного региона или даже одной доступной сторадж‑зоны внутри региона для минимизации задержек на сотни миллисекунд.
Как AI‑нагрузки усиливают Data Gravity
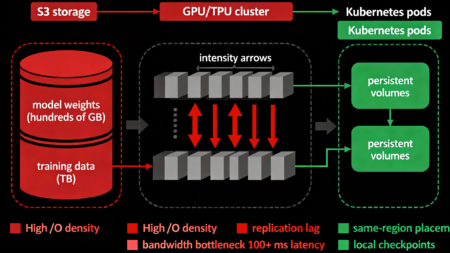
Современные AI‑нагрузки существенно усиливают эффект Data Gravity в инфраструктуре Serverspace за счёт экстремально высокой интенсивности обращения к массивным датасетам и критической необходимости в низкой задержке доступа на уровне микросекунд.
- Высокая плотность I/O и bandwidth-bound вычисления при генеративных моделях. Генеративные модели требуют частого и объёмного чтения больших параметрических весов (от сотен гигабайт до нескольких терабайт) и обучающих наборов данных, что приводит к экстремально высокой плотности операций ввода-вывода (I/O). Инференс больших языковых моделей с сотнями гигабайт весов физически невозможен без локализации ресурсоёмких данных максимально близко к вычислительным узлам (GPU/TPU) из-за сетевого лага, который может составлять 100+ мс на каждый обход модели, и критических ограничений пропускной способности на 10–40 Гбит/с между регионами.
- ML‑пайплайны, tight coupling с хранилищами и persistent state. Обучение моделей, инференс и log‑аналитика в ML‑пайплайнах выполняются с частым обменом данными (checkpoints, model updates, gradient synchronization), что создаёт высокий replication lag при удалённом хранении. Kubernetes‑кластеры с persistent volumes жёстко привязывают исполнительные контейнеры и pods к конкретным регионам, где данные размещены, чтобы минимизировать latency и предотвратить узкие места при горизонтальном масштабировании и распределённом обучении.
- Региональные зависимости, экспоненциальные расходы на трафик и vendor lock-in. Каждый межрегиональный вызов к объектным хранилищам ведёт к росту исходящего трафика, что напрямую увеличивает расходы бюджета облака (часто экспоненциально при PB-scale данных). Специфика Serverspace и её цен на egress-трафик требует оптимизации архитектуры размещения, чтобы AI‑нагрузки обрабатывались исключительно в регионах с высокой плотностью данных, минимизируя накладные сетевые и финансовые издержки в объёме 10 000–100 000 USD в месяц для крупных компаний.
Таким образом, AI‑запросы и ML‑процессы не просто эксплуатируют Data Gravity, но кардинально её усиливают на порядки: вычисления и данные оказываются «жёстко сцеплены» тесными зависимостями на уровне сетевых протоколов (TCP, UDP, QUIC), операционных систем (kernel buffers, page caching) и облачных сервисов (availability zones, network policies), что требует комплексного и проактивного подхода к региональному размещению и оптимизации трафика.
Методы смягчения эффекта Data Gravity в Serverspace
В Serverspace применяется комплекс современных методов и архитектурных паттернов, позволяющих минимизировать негативные последствия Data Gravity и повысить эффективность работы с распределёнными данными и AI‑нагрузками:
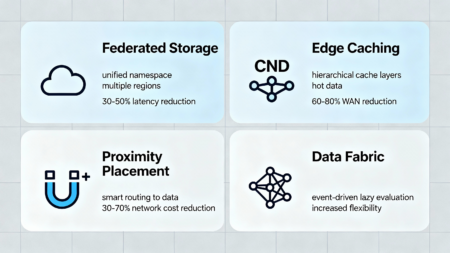
- Federated Storage и multi-cloud orchestration. Гибкое объединение объектных хранилищ разных регионов Serverspace позволяет создать единую виртуальную среду с унифицированным namespace, где данные физически расположены в нескольких локациях (RU, NL, KZ), но логически доступны как единый ресурс через единый API. Это снижает latency, упрощает управление доступом и позволяет вычислениям «оседать» ближе к данным, минимизируя межрегиональный трафик при сохранении гибкости размещения.
- Edge‑кэширование и hierarchical caching layers. Использование промежуточных узлов CDN и локальных cache-layers для кэширования часто запрашиваемых данных (hot data) ускоряет отклик и существенно снижает нагрузку на основные стораджи и WAN-каналы. Это критично для аналитических и BI‑запросов с высокой интенсивностью чтения (100+ RPS), позволяя приблизить данные к потребителю на 50–200 км через edge nodes без необходимости полной репликации массивов данных в каждый регион.
- Multiregion‑репликации с proximity‑placement и smart routing. Автоматическая политика размещения рабочих нагрузок в регионах, максимально приближённых к месту хранения основных датасетов, снижает сетевые задержки на 10–50 мс и затраты на outbound‑трафик на 30–70%. Это достигается через механизм proximity‑placement и интеллектуальный routing, позволяющий распределять вычислительные job в зависимости от локации данных, текущей network congestion и особенностей физической инфраструктуры Serverspace.
- Data Fabric‑архитектура с интеллектуальной оркестрацией. В рамках этой архитектуры используется унифицированная шина данных (data mesh или data platform), которая обеспечивает прозрачное и асинхронное взаимодействие AI‑потоков, ETL‑процессов и микросервисов, позволяя гибко управлять перемещением, трансформацией и кэшированием данных, минимизируя избыточные пересылки и оптимизируя нагрузку на сетевые каналы и хранилища через event-driven архитектуру и lazy evaluation.
Эти методы в комплексе позволяют Serverspace не только эффективно бороться с ограничениями Data Gravity, но и строить принципиально новую парадигму — «умную гравитацию», где вычисления и данные грамотно распределяются и ориентируются рядом друг с другом на основе ML-предсказаний, обеспечивая максимально высокую производительность и финансовую эффективность в масштабе.
Рекомендации для архитекторов
При проектировании и оптимизации облачной архитектуры с учётом эффекта Data Gravity в Serverspace важно подходить к размещению AI‑нагрузок и данных системно и проактивно, чтобы добиться максимальной производительности, масштабируемости и оптимизации затрат на протяжении всего жизненного цикла приложения.
- Планировать AI‑нагрузку федеративно, а не монолитно. Распределение вычислительных задач между несколькими регионами с учётом proximity к данным и текущего сетевого состояния помогает снизить латентность на 20–40% и уменьшить outbound‑трафик на 30–50%, что критично для масштабируемых ML‑ и BI‑сценариев. Рекомендуется использовать data-affinity scheduling в Kubernetes и smart load balancing между регионами.
- Использовать детальный мониторинг throughput, latency, replication lag и network congestion. Важно настроить comprehensive observability и контролировать пропускную способность каналов между регионами, время репликации данных, packet loss rate и CPU/memory utilization на сетевом уровне, чтобы вовремя выявлять узкие места и адаптировать стратегию размещения вычислительных ресурсов. Рекомендуется интегрировать метрики в Prometheus/Grafana и настроить автоматические alerts при превышении thresholds.
- Учитывать FinOps‑аспекты Data Gravity и cost optimization. При планировании бюджета и стоимости облачной инфраструктуры необходимо учитывать дополнительные расходы на межрегиональный трафик (30–50% от базовой стоимости при масштабировании), репликацию и standby-ресурсы, особенно при масштабировании AI‑нагрузок и работе с petabyte-scale multiregion‑хранилищами. Оптимизация архитектуры должна быть направлена на баланс между latency (целевая < 50 мс), throughput (целевая > 500 Мбит/с) и стоимостью (целевая < $0.05 за ГБ в месяц) через использование tiered storage, cold data archival и intelligent caching.
Таким образом, успешное управление эффектом Data Gravity требует комплексного, data-driven и финансово-осознанного подхода к архитектуре, включающего грамотное размещение данных и вычислений, детальный сетевой и финансовый мониторинг, а также постоянную оптимизацию и адаптацию к меняющимся требованиям бизнеса.
Эффект Data Gravity — это не ошибка проектирования или недостаток облачной инфраструктуры, а естественное и неизбежное следствие роста объёмов данных в современных распределённых облачных системах. Чем крупнее и плотнее становятся хранилища данных, тем сильнее вычислительные процессы буквально "притягиваются" к месту их размещения на уровне физики сетей и экономики затрат, оказывая прямое влияние на архитектуру приложений, топологию сетевых соединений, параметры производительности и финансовые издержки.
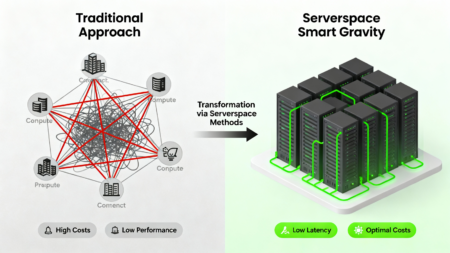
Serverspace, учитывая специфику растущих AI‑нагрузок, потребности в низкой латентности и масштаб multiregion‑хранилищ, предлагает эффективные и инновационные механизмы управления этим эффектом — от федеративного хранения и многоуровневого edge‑кэширования до умного proximity‑placement и унифицированной Data Fabric‑архитектуры. Это позволяет создавать парадигму «умной гравитации», где данные и вычисления целенаправленно ориентируются и направляют друг друга туда, где получается минимальное сетевое латенси, максимальная пропускная способность и оптимальное соотношение стоимости и производительности.
Глубокое понимание и проактивное управление эффектом Data Gravity становится ключевым фактором успеха при построении масштабируемых, высокопроизводительных, надёжных и экономически эффективных облачных решений, которые отвечают амбициозным требованиям современного бизнеса, быстро растущих AI‑приложений и критически важных систем обработки данных в Serverspace.



