
Современные приложения всё чаще работают в контейнерах — это удобно, масштабируется и прозрачно в управлении. Мы привыкли доверять телеметрии: если в Grafana график показывает, что контейнер потребляет «стабильные» 200 МБ памяти и 150m CPU — значит, всё под контролем. Но реальность гораздо сложнее.
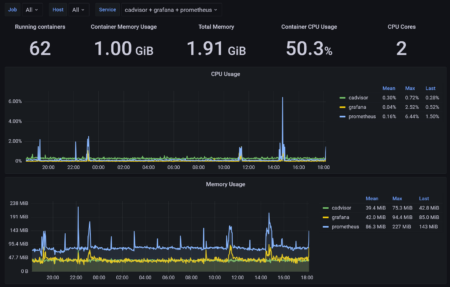
Любой инженер, который сталкивался с внезапным ростом счетов за облако или необъяснимыми просадками производительности, знает: метрики порой врут. Контейнер — это не изолированный процесс, а часть общей экосистемы узла, runtime'а и оркестратора. И внутри этой экосистемы происходят десятки процессов, которые не попадают в отчёты мониторинга, но напрямую влияют на использование ресурсов.
Проблема усугубляется тем, что большинство инструментов визуализации показывают усреднённые данные и не учитывают скрытые накладные расходы — сетевые буферы, sidecar-сервисы, фоновые процессы и runtime-overhead. В итоге компания может тратить в 1,5–2 раза больше вычислительных ресурсов, чем показывают диаграммы, а реагировать на такие отклонения будет уже слишком поздно.
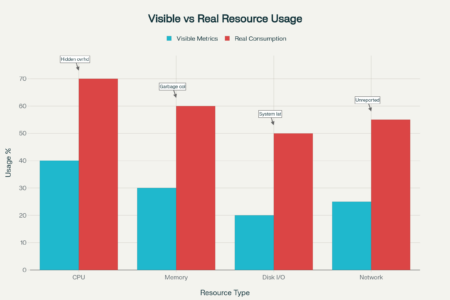
Разберём пять скрытых причин, по которым ваши контейнеры "едят" больше, чем отражают метрики. Каждая причина будет дополнена типовыми симптомами и способами диагностики, чтобы вы могли не только увидеть источник перерасхода, но и внедрить системный контроль над ним.
Неполная изоляция ресурсов в контейнере
Одно из распространённых заблуждений — полагать, что контейнер живёт в полностью отдельной "коробке" и использует только те ресурсы, что выделены в его конфиге. На практике контейнеры в Linux опираются на механизмы cgroups и namespaces, которые ограничивают и сегментируют ресурсы, но не создают абсолютной изоляции.
Это значит, что процессы внутри контейнера могут разделять ресурсы с другими контейнерами и с самим хостом. Например, ядра CPU физически одни и те же, а планировщик просто перераспределяет их время между задачами. Метрики в этом случае могут показывать "нормальное" значение загрузки, хотя фактическое потребление вычислительных мощностей выше — за счёт косвенных процессов, которые контейнер использует, но которые мониторятся отдельно.
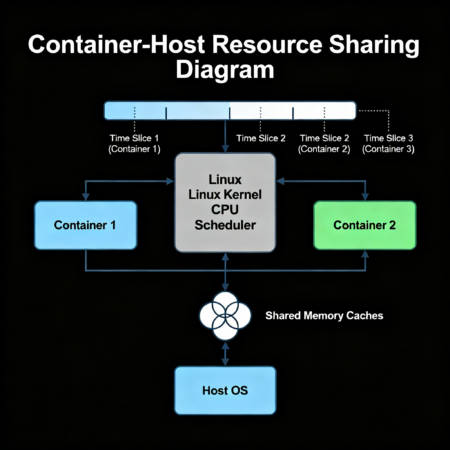
Как выявить проблему
- Сравните данные внутри контейнера (top, free -m, ps aux) с данными на уровне узла через htop или glances.
- В Kubernetes используйте kubectl top pod и kubectl top node — расхождения в показателях часто указывают на проблему.
- Проверьте использование page cache: cat /proc/meminfo | grep -i 'cache'
- Используйте флаги --all-namespaces при просмотре метрик, чтобы учесть все контейнеры, включая те, что запустил сам оркестратор.
Мини-чеклист профилактики
- Явно ограничивайте доступ контейнера к ресурсам хоста (в том числе volume mounts).
- Используйте метрики не "внутри" контейнера, а на уровне пода или ноды для реальной картины.
- Регулярно проводите аудит overhead в целом кластере, а не только на уровне одного приложения.
Overhead со стороны runtime и инфраструктуры
Контейнеризация — лишь одна часть общей инфраструктуры, в которой сервисы работают. Помимо контейнера и приложения, существует множество слоёв, которые потребляют ресурсы, но часто остаются незамеченными в стандартных метриках.
В первую очередь это runtime-окружение — Docker Daemon или containerd, который запускает и управляет контейнерами, а также сетевые плагины, системные журналы и драйверы хранения данных. Каждая из этих подсистем вносит свой неизбежный overhead, который не всегда корректно учитывается в популярных инструментах мониторинга.
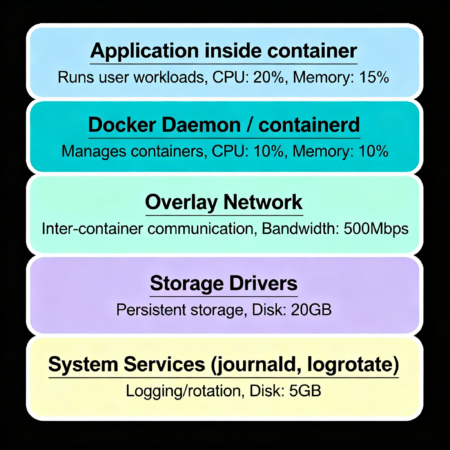
Причины скрытого потребления ресурсов
- Docker Daemon / containerd: Управляющие процессы могут потреблять CPU и память, особенно при масштабных операциях по созданию и удалению контейнеров, а также при взаимодействии с реестрами образов.
- Overlay-сети и CNI-плагины: При работе с overlay-сетями (например, Calico, Flannel) происходят дополнительные операции по маршрутизации, шифрованию трафика и NAT, которые усложняют подсчет фактического использования сетевых ресурсов.
- Драйверы хранения: File system драйверы (overlay2, aufs) добавляют уровень абстракции, ведущий к дополнительным операциям чтения/записи и кешированию. Этот дополнительный I/O часто не отражается явно в метриках контейнера, но негативно влияет на производительность узла.
- Системные службы journald, systemd и logrotate: Логи, генерируемые контейнерами, обычно направляются в хостовую систему. journald и logrotate обрабатывают их накопление и архивирование, что потребляет CPU и дисковые ресурсы вне зоны видимости контейнера.
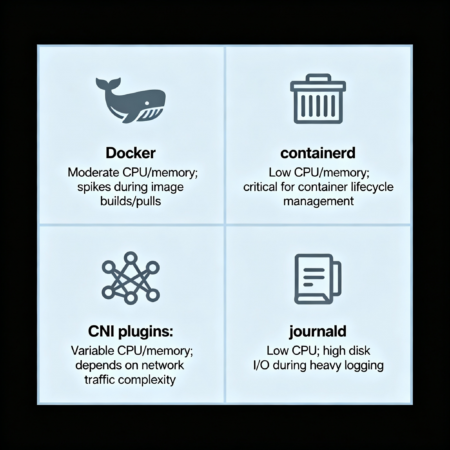
Таблица: видимые и скрытые источники потребления
| Источник | Показывается в контейнерных метриках | Реальный вклад в потребление |
|---|---|---|
| Приложение внутри контейнера | Да | Да |
| Sidecar и вспомогательные контейнеры | Частично | Да |
| Docker daemon / containerd | Нет | Да |
| Overlay-сеть и CNI плагины | Нет | Да |
| Storage драйверы | Нет | Да |
| journald и logrotate | Нет | Да |
Рекомендации по управлению overhead
- Настроить отдельный мониторинг для системных процессов и daemon-ов (например, node_exporter с детализацией по systemd и docker).
- Оптимизировать логирование контейнеров: использовать уровни логирования, применять лог-агрегаторы с фильтрацией.
- Периодически обновлять драйверы хранения и сетевые плагины, чтобы минимизировать накладные расходы.
- Планировать обновления и операции с контейнерами в промежутках низкой нагрузки, чтобы снизить влияние runtime-обслуживания.
Ошибки в лимитах и запросах Kubernetes
Kubernetes предоставляет мощные механизмы управления ресурсами через параметры requests и limits, которые помогают оркестратору эффективно располагать контейнеры и обеспечивать качество обслуживания (QoS). Однако неправильная или неполная их настройка часто приводит к искажениям в отображении метрик и на практике — перерасходу ресурсов и нестабильной работе приложений.
Разница между Requests и Limits
- Requests — гарантированный минимум ресурсов, которые Kubernetes учитывает при планировании пода на узел.
- Limits — верхняя граница ресурсов, которую контейнеру разрешено использовать. При превышении CPU лимита происходит throttling (торможение задач), при превышении памяти — may lead to eviction (выгрузка пода).
Неправильное сбалансирование этих параметров приводит к разным эффектам: контейнер может использовать больше ресурсов, чем видно в XML-мониторингах, или напротив — ограничиваться лимитами, что влияет на производительность.

Как ошибки влияют на метрики и потребление
- Если requests заданы слишком низкие, Kubernetes может упаковать больше подов на узел, вызывая конкуренцию за ресурсы и неучтённые пики нагрузки. Мониторинг покажет, что поды есть, но узел работает "на пределе", а поды испытывают throttling.
- При слишком высоком limit без адекватных requests, приложение может неожиданно использовать ресурсы (CPU/память), но Prometheus и kubectl top покажут только усреднённые значения, что скрывает реальное использование.
- При превышении лимитов по CPU происходят частые throttling-события, которые не всегда сразу видны в метриках, но приводят к ухудшению производительности.
График и анализ
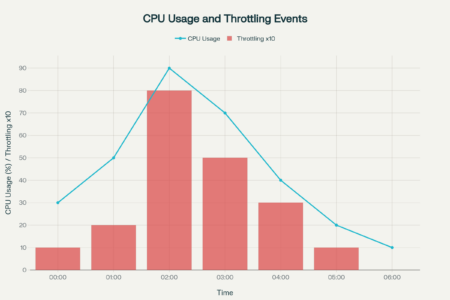
Как правильно настраивать Limits и Requests
- Начинайте с анализа профиля нагрузки приложения под нагрузочным тестом и с замерами на Dev/Stage.
- Устанавливайте requests как минимум на уровень базового потребления, чтобы Kubernetes мог грамотно разместить под.
- Limits должны быть немного выше средних пиковых значений с учётом запасов на непредвиденные нагрузки.
- Используйте метрики Kubernetes QoS классов, kubectl describe pod для диагностики throttling и memory evictions.
Краткий чеклист
- Используйте kubectl describe pod <pod-name> для поиска признаков throttling и eviction.
- Настройте вертикальный автоскейлинг ресурсов (Vertical Pod Autoscaler) для динамической подстройки.
- Интегрируйте алерты на события throttling (например, kube-state-metrics).
- Проводите регулярный аудит и ревизию актуальных limits/requests совместно с бизнес-командами.
Collector- или агент-индуцированное искажение данных
Мониторинговые системы — важная часть инфраструктуры для контроля состояния контейнеров и приложений. Однако парадокс в том, что сами агенты сбора метрик могут потреблять значительные ресурсы, что искажает общую картину потребления и создает дополнительные нагрузки на кластер.
Как агенты влияют на ресурсы
- Нагрузка на CPU и память: Агенты, такие как Prometheus Node Exporter, Datadog Agent или Fluentd, собирают и обрабатывают большое количество данных в реальном времени, что требует циклов процессора и памяти. Особенно это проявляется в больших кластерах с сотнями и тысячами подов.
- Сетевой трафик мониторинга: При использовании push- или pull-моделей возникает дополнительный сетевой трафик между агентами, серверами и базами данных мониторинга, что может привести к задержкам и замедлению приложений.
- Утечки памяти и сбоев: Некорректная конфигурация или баги в агентах могут привести к постепенному росту потребления памяти (memory leak), что существенно увеличивает нагрузку на узлы.
Рекомендации по минимизации влияния мониторинговых агентов
- Используйте легковесные агенты и чередуйте стратегию сбора метрик — например, комбинируйте pull и push модели, чтобы снизить нагрузку на сеть.
- Настраивайте sampling и фильтрацию данных, чтобы не собирать избыточные и малоинформативные метрики.
- Внедряйте горизонтальное масштабирование агентов и разделяйте нагрузку между несколькими инстансами.
- Регулярно обновляйте агенты до последних версий, в которых исправлены известные утечки памяти и оптимизировано потребление ресурсов.
- Мониторьте сами агенты как отдельный сервис с алертами на аномальное потребление памяти и CPU.
Краткий чеклист
- Проверьте текущую нагрузку от агентов командой top или htop на узлах.
- Проанализируйте сетевой трафик мониторинга, чтобы исключить узкие места и "горячие" точки.
- Применяйте лог-фильтры и снижайте уровень детализации логов для Fluentd или аналогичных агентов.
- Используйте lightweight экспортёры вместо полноценных агентов, где возможно (например, node_exporter вместо full datadog agent).
- Настройте регулярную очистку и переработку данных мониторинга, исключая устаревшие или дублирующие метрики.
Рассмотрены пять скрытых причин, по которым контейнеры могут потреблять значительно больше ресурсов, чем показывают привычные метрики. От неполной изоляции ресурсов и фоновых утечек в sidecar-контейнерах до невидимого overhead со стороны runtime и инфраструктуры, ошибок в Kubernetes Limits/Requests и влияния мониторинговых агентов — все эти факторы создают разрыв между видимыми показателями и реальной нагрузкой.
Понимание и диагностика каждой из этих причин позволяет не только точнее оценивать эффективность использования облачных ресурсов, но и существенно снизить риски перерасхода бюджета и непредвиденных простоев. Важно не ограничиваться только поверхностным анализом метрик внутри контейнера, а смотреть на полную картину — включая узлы, runtime, вспомогательные сервисы и инструменты мониторинга.
Рекомендуется выстраивать системный подход к аудиту и мониторингу, внедрять продвинутые методы корреляции данных и автоматизации алертов, а также оптимизировать конфигурации ресурсов и логику работы мониторинговых агентов. Это поможет повысить видимость реального использования ресурсов и качественно улучшить управление корпоративной облачной инфраструктурой.
Начните с простого — проведите ревизию текущих метрик и наладьте мониторинг на уровне ноды и runtime. После — постепенно расширяйте аудит до оптимизации запросов Kubernetes и нагрузки со стороны агентов. Такой проактивный подход обеспечит стабильность, эффективность и экономию в работе контейнерных приложений.
FAQ
- Вопрос 1: Почему Kubernetes не всегда показывает точные данные по CPU использования контейнера?
Ответ: Kubernetes опирается на cgroups для сбора метрик, но из-за общей нагрузки на узел и планирования задач фактическая загрузка CPU может отличаться от показателей, особенно при использовании overlay-сетей и фоновых процессов. Усреднение метрик и задержки сбора также влияют на точность. - Вопрос 2: Как sidecar-контейнеры влияют на потребление ресурсов основного приложения?
Ответ: Sidecar-контейнеры, например для логирования или проксирования, работают в том же поде, но потребляют отдельные ресурсы. Метрики основного контейнера часто не учитывают их нагрузку, что приводит к недооценке общего потребления пода. - Вопрос 3: Зачем мониторить ресурсы на уровне узла, а не только контейнера?
Ответ: Контейнерные метрики показывают использование внутри ограничения, но ресурсами узла управляет ядро и runtime, которые также потребляют CPU и память. Мониторинг узла позволяет увидеть полный оверхед и избежать сюрпризов с перерасходом. - Вопрос 4: Как правильно выставить Limits и Requests, чтобы избежать throttling?
Ответ: Начинайте с анализа профиля нагрузки приложения, устанавливайте requests как минимум на базовый уровень потребления, а limits чуть выше максимальных пиков. Используйте инструменты вертикального автоскейлинга и мониторьте события throttling. - Вопрос 5: Как уменьшить влияние агентов мониторинга на потребление ресурсов?
Ответ: Используйте легковесные агенты, применяйте семплирование и фильтрацию данных, распределяйте нагрузку на несколько экземпляров агентов и регулярно обновляйте их для исправления утечек памяти и оптимизации работы.



